由於各家資料庫或不同實做角度看會使用不同的單字,
我們常常會使用 record、row、tuple 這三個單字來表示每一筆資料,筆者這裡預設使用record代表。table、collection 這三個單字來表示,筆者這裡預設使用table代表。
寫資料時,我們第一個就是拿出一張紙開始寫字,而資料庫呢?
就是拿出一張表,之後開開始寫 records。
而我們知道資料結構決定了存下資料的查詢與存取速度,
因此必須了解資料將會是如何存進資料表之中。
這一章節,將會有初步的了解資料庫管理系統是如何尋找空位儲存,
與使用何種方式將資料存下,了解其優勢與劣勢。
資料庫系統,主要使用了兩種 Table 儲存方式。
| DBMS | HOT | IOT |
|---|---|---|
| oracle | o | o |
| postgres | v | x |
| mysql | x | o |
以下說明 Postgres 為例。
DBMS 之中,每個儲存調度的單位為 Page,page 的 page size 通常為 8Kb。
非常單純,只有存滿 8KB 記得換存到下一個 Page,沒有其他意思。

再介紹 Heap Organized Table 之前,需要先了解 Heap page。
這裡面存的是 record 的pointer,並非存整筆 record 喔!
大致組成的長相如下,有一個 page header,8k 的空間,由下往上填滿。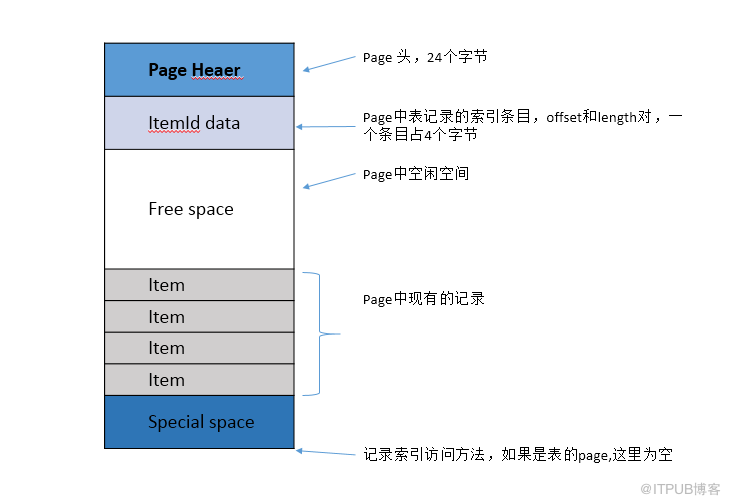
FSM 會幫助 dbms 尋找有哪些 free heap page 可以放新的資料進去。 FSM 的設計主要有兩種算法
由一種規則所建立的 complete binary tree
e.g. max heap: root 為最大,到 leaf 最小
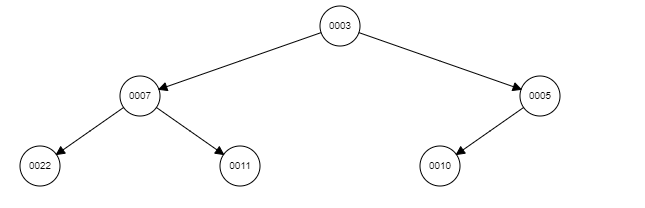
注意: Heap 結構不是 Hash!!! 千萬不要再搞混。
這裡的 Binary Tree 是 complete binary tree 其實就是一個 非典 Max Heap Tree,\。
leaf 存著 heap page free space 空間,這裡稱為 map value,
每個 node 都存著該條路最大的 map value,
所以 parents node 為兩 child node 的最大 map value。 (parents= Max(left child,right child)),
到了 root 就可以知道目前最空的 heap page 囉!
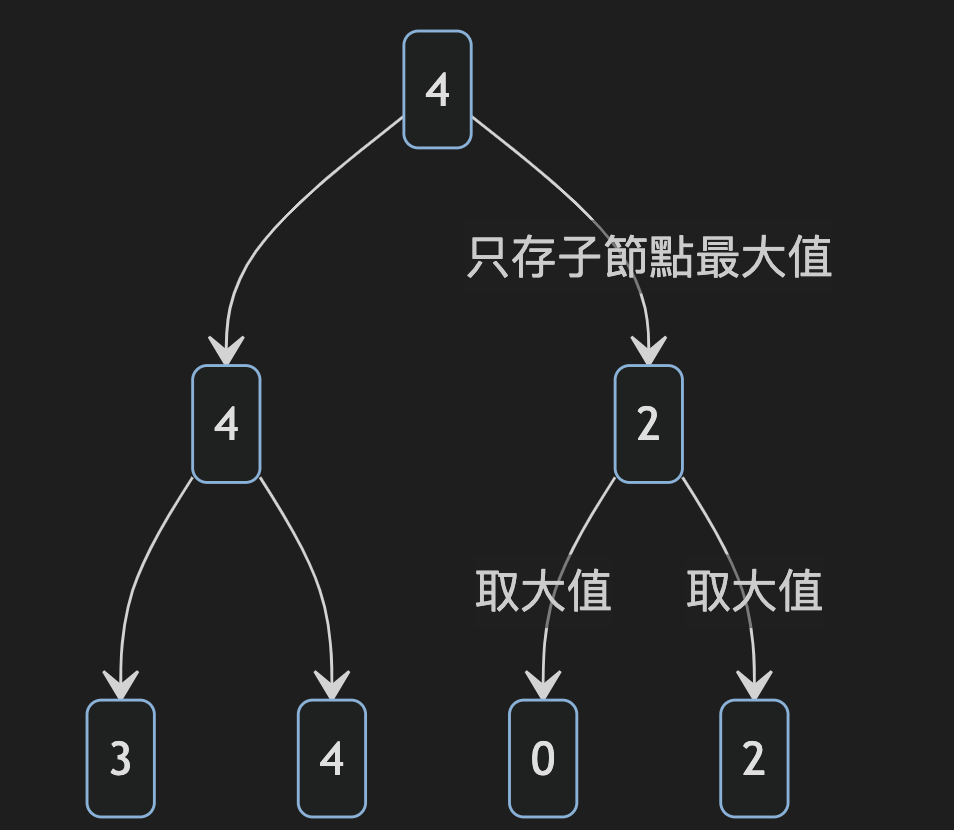
存 record 時,由於 root 就是最大的 heap page free space,
所以插入前只需要判斷 root 節點是否有剩餘的空間可以插入,
即可馬上地知道是否需要新建立新的 heap page。
存 record 時,將 record 由 FSM 決定好要存在哪個 heap page 之中,
存完後再以冒泡的形式一次修改 parent node。
因每次存 record 時,都是有 FSM Tree 決定存入哪個 Heap page 之中,
因此 Heap 空間中對於儲存的資料是沒有順序保證的。
Postgres Heap page 存了 8kb 的 records pointer,
FSM 所建立的 Binary Tree 也是使用 page 所存下,這裡我們稱之為(FSM tree)同時也有 page 的 8k 限制。
隨著 Table 的 records 的增加,FSM Tree 也會隨之變大,甚至大過於 Heap page 的大小。
這時,我們必加入新的 FSM Tree。加入新的 FSM Tree,就必須解決跨 FSM Tree 的問題。
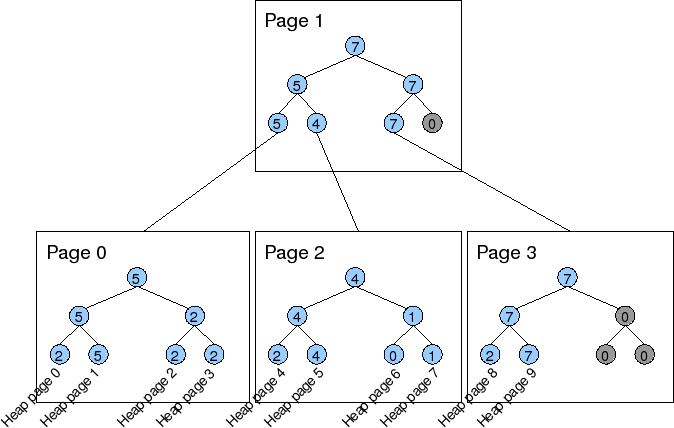
這時引入了 Hight-Level 算法,在這些 FSM Tree 之上,再加上一層 FSM Tree,類似延長線再接延長線的概念。
下圖我們看到 Page0、2、3 個別存著一個 FSM Tree,而他們上面又接著 Page1,使用 FSM Tree 管理著
這裡先了解一下 Index 是什麼樣的資料結構,通常資料庫最常用的預設 index type 為 B+Tree(還有其他 index type 後面 Query 章節將會介紹)。
Index 類似於查字典時後面所使用的索引,有些人用部首,有些人用注音查字,而且同類的也會放在一起,可以依照需求查詢,速度勝於從第一頁翻到最後一頁。
假設我們存入 record 時,也能按照著 record 的某個 key 作為 index,
存下 record 同時達到建 index 的效果呢?這時指的就是我們的 Index Organized Table (IOT)。
以下說明 innodb 為例
將會先介紹 index 的 B+Tree,再介紹 Index Organized Table 如何使用 B+Tree 來建立 records。
B Tree order 3 其實就是一個 2-3 Tree。
其中 order 就是指最多可以有幾個 degree(child node)。
而 B+Tree 就是將 leaf node 再使用 pointer 做相連,這樣範圍查詢是,就可以達到往隔壁找就抵達,不需要再從 root 開始尋找。
經常使用這個結構作為 index,每個 node 之中,存了被作為 index 的 key 的 value。
下圖為 B+Tree 結構。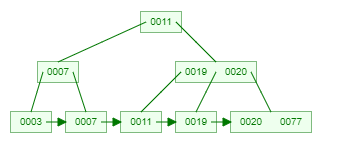
存 record 時,我們將會使用主鍵作為 index,將該 key 存入 b+tree 之中,
每個 node 有主鍵與該 record 的 pointer。
Clustered Index 就是透過主鍵所建立的 B+Tree,並且有用真實 record 的 pointer,
Table 塞資料時,就是按照著這個結構存下的。
因存下資料的結構是由主鍵所影響,因此對於儲存的資料是有順序保證的。
Secondary Index 就是我們正常的 index 了,
每個 node 有被作為 index key 的 value 與該 record 的主鍵
注意!這裡存的是 record 的主鍵,並非真實 record 的 pointer
因此,當我們使用 Secondary Index 取資料時會先取出主鍵,再拿那些主鍵去 Clustered Index 中,取出真實的資料。
因 index 不是這章節的主角,因此先做簡單介紹,後續再做詳細的討論。
我們了解了 Heap Organized Table (HOT)與 Index Organized Table (IOT)兩者的儲存結構,可以看到。
HOT 利用 Heap Page 切成多塊儲存個體透,過了 FSM 找尋可用 Heap Page,再使用 Hight Level 串接 FSM Tree,非常單純的只有存下 record。
順帶一提,這裡預設的 index 也是使用 b+tree,存法為 Clustered Index,即 leaf node 直接就是 records pointer。
1。 能快速知道 table 內有沒有空間剩下。如果沒有了便要告訴 RDBMS 去 format 新的空間出來。
2。 讓多個 worker 同一時間找到各自所需空間,而又不互相干擾。
3。 優先返回近期被使用過的空間,提升 IO 效率(cache hit rate)。
IOT 透過了 B+Tree 存下了 Clustered Index,並帶上 record 的 pointer,
單單利用一棵樹存下全部的 records,若 records 越多,Clustered Index 就會越來越龐大。
| item | IOT | HOT |
|---|---|---|
| data structure | B+Tree | FSM Tree+HeapPage |
| node value | PK+Pointer | map value |
| leaf node value | PK+Pointer | HeapPage Pointer |
| default index | Secondary Index | Clustered Index |
| index node | key+PK | key+Pointer |
| index need search clustered Index | Yes | No |


 iThome鐵人賽
iThome鐵人賽